Before Start
-
Make sure you have some virtual machines (VM) launched on Amazon Web Service (AWS).
-
I launched four VMs, you can choose to launch more. And the Hadoop Version I installed is Hadoop-2.6.5, this configuration works for Hadoop-2.X.X versions. You can take my blog as an example and configure your VMs.
-
At the beginning of each Section, it tells whether you have to do the configuration for all VMs or just one of them.
Note: recently I noticed that if you keep your Hadoop idling on AWS, AWS may consider the connection between your VMs as DOS Attack and shut down network ports used by Hadoop.
Objectives
Build fully distributed Hadoop on the cluster formed by these four VMs.
SSH Passphrase Free Connection
For each VM, type the following command in the terminal to generate a pair of RSA keys (i.e., public key and private key):
ssh-keygen
Then press “enter key” for file and passphrase, which means setting these values as default.

Then type the following in the Terminal of each VM:
cd ~/.ssh
By typing this, you enter the default directory of ssh, where should have at least two files now: id_rsa and id_rsa.pub, you may also have another file named know_hosts or authorized_keys.
RSA Encryption Algorithm allows us to use public and private key pairs to safely connect two hosts. Private key, which saves in id_rsa should be kept in your own computer, and public key, which saves in id_rsa.pub, are shared with other hosts (computers). By doing this, other computers can use this public key to communicate with your computer safely. Surely, you have to make sure only give your public key to the computers you trust.
And the file known_hosts or authorized_keys are used to save other computers’ public keys. So if computer A has computer B’s public key save in A’s authorized_keys file, then computer A and computer B can communicate with each other safely.
So, obviously, we have to share public keys among all VMs, so that they can communicate with each other. Because Hadoop is a parallel computing engine, all the works are done by computers in the cluster. If these computers can not communicate with each other, how can they cooperate and complete their jobs. Just in case you may need to use localhost, you can also save one copy of each computer’s public key to its authorized_keys.
Assuming you are not familiar with command line, you can just use copy and paste to do this public key sharing. After doing that, for each computer, it should have four (I have four VMs) public keys save in authorized_keys files.
After doing that, now you have successfully configured SSH passphrase free connection between all VMs. Now I can SSH to the computer with private ip address “172.31.11.234” using the following command:
ssh 172.31.11.234
Certainly, I can also use its public address.
However, typing IP address is tedious and prone to make mistakes.. So we can save the name of each computer and their corresponding IP addresses in a “phone book”, and connect to each other using their name instead of typing ip addresses.
Do the following for all VMs. We can type the following command in the Terminal to edit “phone book” of each computer:
sudo vim /etc/hosts
Add the following entries into it:

These four lines are the contact info for each computer. For instance, the IP address “172.31.11.234” is for the computer named “master”.
After adding these four contact info in each computer’s phone book. We can use the following command to connect to another computer:
ssh master (or slave1, slave2, slave3)
Install JAVA
For each VM, you have to install JAVA. So the following commands are necessary for all VMs.
First of all, type the following command in the Terminal to update the repository of apt-get (which can be considered as App Store in your iphone):
sudo apt-get update
Then type the following command to install Java
sudo apt-get install default-jdk
After executing, you can find your java at the directory of /usr/lib/jvm, let’s take a look at it:
cd /usr/lib/jvm
As shown in the figure, these are JDKs (Java Development Kit) I see in my VM, java-8-openjdk-amd64 is the latest one:

Add JAVA_HOME information to file ~/.bash_profile:
vim ~/.bash_profile
Add the following:
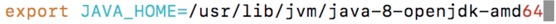
Source this file and makes it taking effect:
source ~/.bash_profile
Download and Extract Hadoop
This section only needs to be done in “Master” VM. What we do is configure Hadoop in one VM, and then send a copy of this configured Hadoop to other VMs.
Click in to Apache Hadoop Download Page, and download the binary file of Haodop.

Go back to home directory (because I wanna install Hadoop in my home directory. You can choose any other directory you prefer, just make sure you change all the related path info):
cd ~
And typing the following command in Terminal to download:
wget http://apache.mirrors.ionfish.org/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
And using the following command to extract Hadoop:
tar -xvzf hadoop-2.6.5.tar.gz
Now, type the following command to get the absolute path of your Hadoop, and keep this path in mind:
cd hadoop-2.6.5
pwd
My Hadoop’s abusolute path is /home/ubuntu/hadoop-2.6.5.
Configure ~/.bash_profile
You have to do this for all VMs.
For each VM, edit ~/.bash_profile :
vim ~/.bash_profile
Add the following content:
export HADOOP_HOME=/home/ubuntu/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
For HADOOP_HOME, it is the absolute path of my Hadoop, you can change it to yours. And make sure all the VMs save the Hadoop at the same directory. Now this is how my ~/.bash_profile looks like:

Similarly, source my ~/.bash_profile:
source ~/.bash_profile
Configure Hadoop
This section only needs to be done in “Master” VM.
Firstly, enter Hadoop configuration directory:
cd hadoop-2.6.5/etc/hadoop/
The following files need to be configured:
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- hadoop-env.sh
- slaves
- masters
The following path configured is based on my Hadoop’s absolute path, make sure change to your corresponding path.
For core-site.xml, we add the following:
<configuration>
<property>
<name>fs.defaultFS</name> <!-- this is to configure HDFS-->
<value>hdfs://master:9000/</value> <!--"master" is configured by use in the file /etc/hosts -->
</property>
<property>
<name>hadoop.tmp.dir</name> <!--configure directory to save temp file-->
<value>file:/home/ubuntu/hadoop-2.6.5/tmp</value> </property>
</configuration
For hdfs-site.xml, add the following:
<configuration>
<property> <!--directory of namenode file -->
<name>dfs.namenode.name.dir</name>
<value>file:/home/ubuntu/hadoop-2.6.5/dfs/name</value>
</property>
<property> <!--directory of datanode file -->
<name>dfs.datanode.data.dir</name>
<value>file:/home/ubuntu/hadoop-2.6.5/dfs/data</value>
</property>
<property> <!--This configure the number of replicas-->
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
For mapred-site.xml, notice that there is no mapred-site.xml in this directory, but it has mapred-site.xml.template, so you have to first create an mapred-site.xml by typing the following command:
cp mapred-site.xml.template mapred-site.xml
And add the following content to it:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
And the following is for yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property> <!--master means the same as previous file-->
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
Then, configure Hadoop environment variables, add the following to your hadoop-env.sh:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_PREFIX=/home/ubuntu/hadoop-2.6.5
# Set hadoop configuration path
export HADOOP_CONF_DIR=/home/ubuntu/hadoop-2.6.5/etc/hadoop/
export HADOOP_HOME=/home/ubuntu/hadoop-2.6.5
# add hadoop packages
for file in $HADOOP_HOME/share/hadoop/*/lib/*.jar
do
export CLASSPATH=$CLASSPATH:$file
done
for file in $HADOOP_HOME/share/hadoop/*/*.jar
do
export CLASSPATH=$CLASSPATH:$file
done
Then source hadoop-env.sh file:
source hadoop-env.sh
Add the following to slaves, slave1-3 stands for the other three VMs configured in /etc/hosts:

Change masters file to the following:
master
Send Configured Hadoop to Other VMs
Only do on master VM.
Using the following commands one by one:
scp -r ~/hadoop-2.6.5 slave1:~
scp -r ~/hadoop-2.6.5 slave2:~
scp -r ~/hadoop-2.6.5 slave3:~
Format HDFS And Start Hadoop
In your mater node, using the following command to format name node:
hdfs namenode -format
Then you can use the following two commands to start Hdfs deamon and yarn deamon:
start-dfs.sh
start-yarn.sh
Now if you use jps command on all your VMs, you are supposed to see the following processes on the master node:

And on all slave nodes, you are supposed to see the following processes:

Now, Fully Distributed Hadoop is successfully installed and launched!!
Examples
Let’s run a word count example:
vim WordCount.java
Add the following code into it :
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class WordMapper extends Mapper <Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map (Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class WordReducer extends Reducer <Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int sum = 0;
for (IntWritable val : values){
sum+=val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main (String args []) throws Exception{
Configuration conf = new Configuration ();
Job job = Job.getInstance (conf, "WordCount");
FileInputFormat.addInputPath(job, new Path (args[0]));
FileOutputFormat.setOutputPath(job, new Path (args[1]));
job.setJarByClass(WordCount.class);
job.setMapperClass (WordMapper.class);
job.setReducerClass (WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Type the following command to compile WordCount.java:
javac WordCount.java
Now you will see three class files:

And then pack these three class files into a jar package:
jar cvf WordCount.jar *.class
Now we can have code to run in Hadoop. Now let’s create an input file to test our code:
vim A.txt
Add the following:
you are my sunshine
Then create an input directory in the root directory of HDFS:
bin/hdfs dfs -mkdir /input
Now we have the input in HDFS, and also the code, we can use the following command to run our code using Hadoop:
bin/hadoop jar WordCount.jar WordCount /input /output
The last two parameters set the input path and output path. Output path should not exist on HDFS, Hadoop will create an output path for you. But if we set output directory to be an existing directory, Hadoop will throw an error.
Then you should see the following in your Terminal.
After execution, you can using the following command to retrieve the result from HDFS:
bin/hdfs dfs -get /output
In the output directory, you should see two files: _SUCCESS and part-r-00000. _SUCCESS means you have run your code successfully. part-r-00000 saves your result. You are supposed to see the following in your output directory:
